
点击上方【车云】,关注并查看更多往期内容。
车云按:2017年6月21日-22日,由中国安全产业协会、TIAA车载信息服务产业应用联盟与车云网共同主办的2017年中国安全产业峰会暨首届交通安全产业论坛在北京召开。本文系地平线机器人技术创始人&CEO余凯在大会上的主题演讲,当中对面向未来的自动驾驶技术展开了讨论,并通过实例说明了深度学习将对未来自动驾驶技术带来巨大的变革。

▲地平线机器人技术创始人&CEO 余凯
以下为演讲实录:
感谢能有这么好的机会跟业界的同行来汇报跟交流一下我们在汽车技术方面做的一些工作。我们公司主要是在深度结合新型人工智能的处理器去做自动驾驶的解决方案,所以我介绍一下这方面的工作。
从“端到云”地平线在构建自动驾驶汽车大脑系统
地平线机器人,实际上我们不造机器人,我们造的可以说是机器人的大脑,毫无疑问,如果我们想面向未来,如果能够影响人类生活,最大规模影响每个人从出生医院,产房里面一出来到家里面,然后整个人生的每一个阶段。深刻的影响你生活的机器人是什么呢?我觉得没有比汽车更重要的了。所以如果去做面向机器人技术的话,我觉得毫无疑问是自动驾驶。
地平线现在总部在北京,在中关村,我们同时在南京有研发中心,最近在上海的安亭成立的我们自动驾驶的研发中心。现在我们有200个工程师,其实各种员工加起来,包括实习生将近有400个人,在软件、算法、硬件、处理器的架构设计。
所谓面向未来的自动驾驶,一方面在车这一端,我们要部署先进的人工智能的算法,从感知到定位到环境建模到决策规划到控制。这些算法的复杂性,用今天我们大家通常用的计算平台,比如说CPU是不能去完成的。我们可以看到,除了人工智能的算法在过去几年突飞猛进的发展,同时平行去发展的就看到了从Intel到Nvdia再到Google都在投入做人工智能处理器的研发,在中国当然地平线是作为最早的致力于人工智能处理器变革的一家公司。所以它一定要在车上面去部署这种算法,它需要功耗足够的低,车不能发热,它要足够的安全。另一方面,这还是一个大数据的系统,因为车不断的在感知数据,把新的数据传送到云端,在云端进行并行大规模的训练,然后就构建新的模型再重新部署到车的本地端。所以它也是在云端的一个大数据计算,我们构建“端到云”的这种汽车大脑系统,从软件到硬件。
深度学习的关键是让机器自主学习
谈到深度学习,毫无疑问在过去五六年时间里像旋风一样,从互联网公司影响到传统汽车的行业。从比较学院的这种曲高和寡的研究,到街头巷尾到国家领导人到每一个老百姓都在谈论的AlphaGo下围棋,背后主要都是深度学习的进步。
深度学习实际上是机器学习的一个分支,所谓机器学习是构造一种算法,像人的大脑一样,能够不断的从数据中、从经验中学习变得越来越聪明。80年代末机器学习成为人工智能的主流,传统的机器学习通常是一个一个的步骤,一开始从数据的感知预处理再到特征的提取、特征的变化,最后到预测跟识别,这是典型的机器学习。
过去最后一个步骤是特征提取完了以后怎么做感知。而进入到深度学习,它是把整个系统作为一个框架来看,之前特征的预处理与提取实际上也非常的重要,但它对计算的要求更高,对最后的效果更加的关键。过去这些研究都被忽略了,深度学习的影响把中间所有的步骤都变成自主学习的一个机器,从感知的数据出发,直到最后输出的结果全部都是用大数据的训练。
这些放在五年前,无论是在中国还是在美国,听起来都是天方夜谭,今年已经成为现实。目前最成功的这些计算机识别,语音识别,包括以前我在百度工作的像互联网的广告、搜索,还有今天下围棋这种决策的系统,实际上最好的系统都是基于深度学习的。
在这里面我分享两个例子,我认为是在深度学习的应用取得了一个非常重大的,并对实际的产品对业务产生重大影响的两个实例。
第一个实例是当年在百度的时候,我们做的一个项目,这个项目就是说希望用深度学习去提升搜索引擎的相关性。百度与Google其实都做了类似这样的项目,当然百度比Google早一年做。我们在想一方面怎么用大数据训练,通常用人工去标注数据,我们能够标大概30万个样本,实际上可能就已经很难了。因为标注的成本非常贵,时间也非常的耗时。
能不能用用户自然的数据来训练,而不需要人工标注?实际上,我们是可以去用这样数据的。比如用户输入一个地址,我们关注到这个用户点击的地址,另外一个没有点击。实际上就是点击的网页比另外一个没有点击的对搜索更相关的关键词,我们就可以利用三元组,搜索词,还有点击的网页跟没有点击的网页,三元组成组构成训练的样本。大家可以看到训练样本实际上你没有任何的限制,你可以搜索无穷的获得训练样本,我们可以训练1个亿参数的深度神经网络,这个是在整个搜索引擎的历史上面对所引擎的相关性提升最大的技术。
另外一个例子,这个例子叫AlphaGo,AlphaGo实际上也有很多非常非常让人印象深刻的新技术突破。但它这里面有一个核心的思想,比如说我们最近的AlphaGo 2.0,实际上它没有用任何的标注数据,它也没有用人工的标注数据。它实际上通过虚拟的程序之间的左右互搏,然后不断的去提升它的合力。这种情况的话,也是突破了标注数据对训练强大的一个神经网络带来的限制,它可以自主的去学习。
所以刚才讲的这些事情听起来跟自动驾驶没有关系,但是我从这两个事例里面获得一些启发。首先第一点,在第一个系统里面,用深度神经网络来做排序,这个里面核心的思想是说,与其让人工来标注数据,那我们是不是也可以让它自主的去用户自然数据里面去学习?

第二个例子是下围棋。下围棋是通过自然的数据,利用系统虚拟地去做仿真,从仿真里面去照出虚拟的数据然后再训练这个模型。这两个思想放在一起,它的一个核心的共性是:我们不是在构造一个虚拟的人工系统,而是自主学习人工系统,这点是我今天要讲的主要话题。未来的自动驾驶的汽车,它实际上是自主学习的,而不是被训练的,这点非常重要。这里面一个核心的要素,就是说在训练、学习的时候,它是从自然的数据里面去学习,而不是一个被动的去输入标注的数据。从软件到硬件再到数据,整合构建拥有深度学习能力的自动驾驶系统
其实刚才我已经讲了我今天报告主要的要点。地平线认为构建未来的自动驾驶系统,如果单纯做软件或单纯做硬件都是不行的,单纯在本地端而不在云端构建大数据的系统也是不够的。所以我们要做的叫全栈式技术的开发,从软件到硬件、从本地到云端。
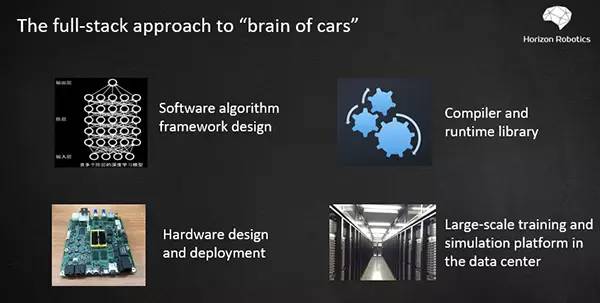
首先软件层面,我们需要克服很多挑战,我认为有三个大挑战。第一个什么让系统从黑箱变成一个白箱系统。第二个是说怎么样让这个系统能够不断的自主学习。第三个是说怎么样让这个软件对硬件友好,因为一定要低功耗、高效率、低延迟,这里面软件跟硬件的配合非常重要。
怎么去构建一个可解释的、人可以理解的深度神经网络呢?我们需要去回顾到整个人工智能的历史。在80年代末的时候,神经网络被提出来热了一阵子却又被冷掉。在90年代基于因果推理的理论导出,实际上是主流,到2011年的时候衰落,因为深度学习又起来。这个历史是循环往复的发展,但是今天看起来Bayes网络所谓的科技实际上可以跟深度网络结合,它同时是白箱子系统,这个是地平线正在做的事情。

这样的一个白箱子系统,可以理解为是一个非常大的Bayes网络,实际上是用一个小的、子的深度神经网络来表示的。这样模块跟模块之间的接口是清晰可定义的,但实际整个的系统它可以端到端的学习。同时在这样一个框架里面,这个系统是一个完全的不断自主学习,白天晚上每一秒钟不断从路上的经验去学习。
另外还有一个好处,因为它接口之间是清晰定义的,所以它能够非常容易的去整合基于规则的系统,基于人工规则的系统。另外一点,就是怎么样去构建一个单个的深度神经网络,使得它是可解释的。
最终关乎到决策,如果决策实际上就要去用到所谓的增强学习的这么一个框架,在这样一个框架,车实际上不仅仅是从每一个司机自然的行为里面去学习,同时它也从仿真的系统里面去学习。这个其实也反映就是我刚才讲的两个观点,从自然数据去学习,通过仿真来学习,跳出标注样本所带来的局限。
另外就是关于硬件,硬件我们关注两个方面,第一个方面就是系统硬件,包括编译器跟运行时的软件,然后来提升软件的运行。同时我们需要从感知到定位到三维建模到预测到推理,实际上我们要根据软件本身的构架适应性重新的去设计它处理器的架构。这个实际上当前在Google的TPU,包括地平线最近在做的BPU,根据软件的硬件重构。
我们可以看到在人工智能时代,实际上整个软件应用所带动处理器的变革其实正在发生。我们可以看到在深度神经网络计算里面,我们传统的ABG跟GPU表现了不同的能力,我们可以看到其实在一年半的时间里面从一个排名大概是排不到前几年的半导体公司到今天成为世界第二大的半导体公司,成为一个一千亿美金的公司,就是因为整个软件应用的驱动带来处理器架构的重构,所带来一个新的机会。
这里面其实也有一些相当的机会,因为软件的算法不断演进,如何使你处理器架构灵活。最灵活的方式其实从电路上面不断改变电路的方式,FPGA实际上在自动驾驶领域有它相当的生命力。当然,最终一旦软件算法本身能够固定下来,那专用集成电路一定是未来的方向,就是所谓的叫ASIC。Google的TPU和地平线的BPU都是在往这个方向走,可以看到在TPU它有最大的计算能力,但是每瓦的计算力实际上是比较低的。ASIC它可以做的最好,但是同时每瓦功耗计算能力能够比现在的GPU提高30倍到50倍,这个是现在产业竞争的焦点。地平线在按照从感知到不断的去增强决策能力的计算。
这个是我们跟Intel在一起合作做的在处理器方面,比如说我们利用低功耗处理器设计可以做实时,对每一个象素级的感知,在非常复杂路面上面对每一个象素,每一个行人,不仅是把它大概的框出来,然后每一个细节的边界都能够做得非常准确的这种处理。然后我们在下一代处理器架构,其实还会从二维的感知到三维语义的感知去发展。我想最终通过硬件跟软件的联合设计,实际上使得传感器能够充分实时的计算,然后去理解在周围它所发生的不光是静态的信息,相对位置的信息,包括动态下一个5中行人跟车辆往哪个方向去走的信息。最终去实现在效率,在延迟,在准确率这方面的话,一个最优的结果,这就是整个产业界现在往前去发展的。
最后,我想谈一下数据,数据量的增长在未来的自动驾驶时代是一个很大的挑战。从现在开始,实际上每一个手机它有多个的传感器,数目越来越多,每一个汽车未来传感器的数目也会越来越多。所以传感器的增长它一定是高于人口的增长。这样的话,数据的增长跟传感器的增长是线性的,计算的增长跟数据的增长是非线性的,因为越来越复杂的算法会被发明,会被提出来。所以这就给计算带来了巨大的挑战。
给大家举一个实际的例子,目前在学术界做计算机视觉,最大的数据集差不多是100万的图像的样本,但是一个自动驾驶汽车一天收集的样本就是600万的高清自动图像。1000台这样的车,在一天所收集的数据,它相当于整个百度的搜索引擎所检索的整个互联网图片的数目。所以一天1000辆自动驾驶的汽车,它所搜集的数据就是这么大的一个量。那么我们怎么去应对这样的一个计算?其实从这个计算另外还有一方面的挑战。
你在真实道路里面搜集的数据,比如说突破千万或者是亿的其实也很难了。但是还有很多的不能被充分暴露出来,所以通过这种仿真让各种情况充分暴露出来,使得上百亿虚拟的公里数在你的数据中心不断的去测试,这个也是自动驾驶的一个必经之路。
最后,总结一下,第一个观点,深度学习在未来一定会导致自动驾驶的革命,就像我们看到很多领域,无论是说计算机视觉,语音识别,还是下围棋,还是很多的人工智能机器人的应用,都被深度学习革命。第二个观点,未来的话自动驾驶的汽车一定是活生生的在不断自主学习的汽车,而不是说在线下你去训练它,训练完了以后再放到路上面不再自我更新。第三个观点,就是深度学习有很多的好处,但是我们一定要应对它的挑战,就是它现在是一个相对黑箱的系统。第四个观点,我认为非常重要的就是说,我们一定要去走所谓的像苹果所信仰的深度软硬件去整合,使得整个系统的效率跟系统的安全性、可靠性得到最优。只做软件或者只做硬件是不够的。
好的,我的分享就是这些,谢谢大家。






时间|热度