近年来智能座舱逐渐呈现出同质化的发展特征,随着AI大模型的爆发(尤其是DeepSeek的影响)有望在智能座舱领域换发新的生机,各车企纷纷下场布局大模型,力争在未来抢占产品体验与AI技术的制高点。

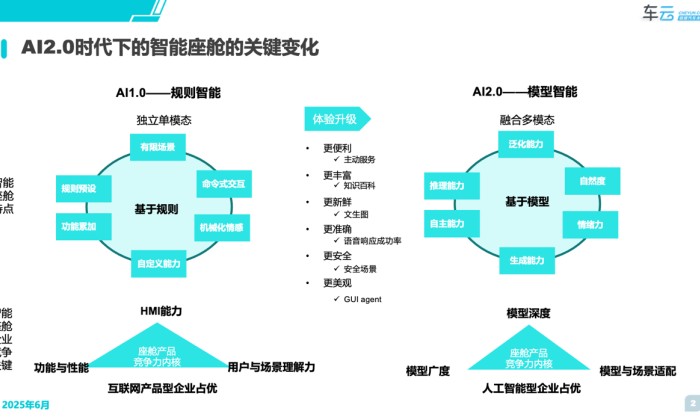
随着大模型的快速发展与落地,智能座舱也从AI1.0时代逐步进入AI2.0时代。从呈现出的关键变化来看,其特点主要表现为从基于规则的智能转向为基于模型的智能。
具体来看:
【AI1.0时代】有限场景+预设规则+功能累加+命令式交互+机械化情感+自定义能力
【AI2.0时代】泛化能力+推理能力+自主能力+自然的交互+情绪化情感+生成式能力
可以预料的是,AI2.0会从人性的六大维度上(懒、贪、馋、快、活、美)得到全面的体验升级。也会推进智能座舱企业从原有的竞争力内核向新的竞争力内核转变。
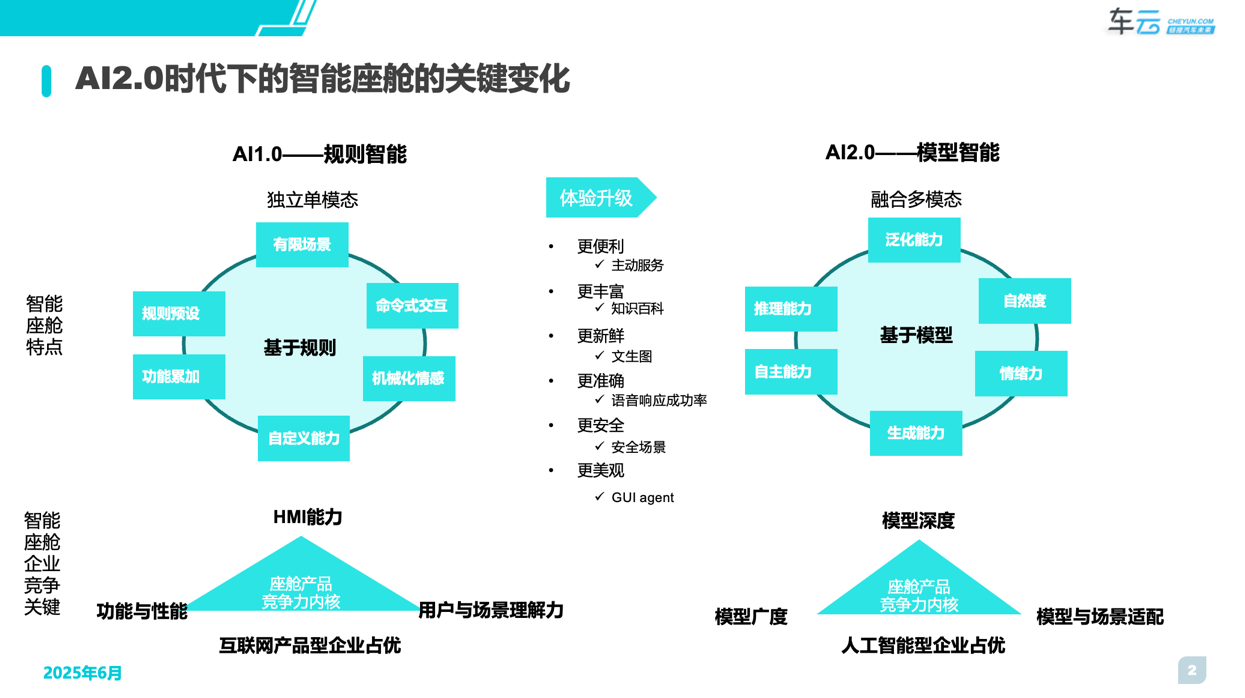
AI大模型作为智能座舱的一部分,在用户端的体验与场景的占比仍旧不够凸显,但其带来的用户体验价值的增益将是巨大的,因此我们将AI评测体系作为CC-1000T智能座舱评测体系的专项体系,分别采用自上而下(从场景看技术)和自下而上(从技术看场景)的思路进行设计与搭建。
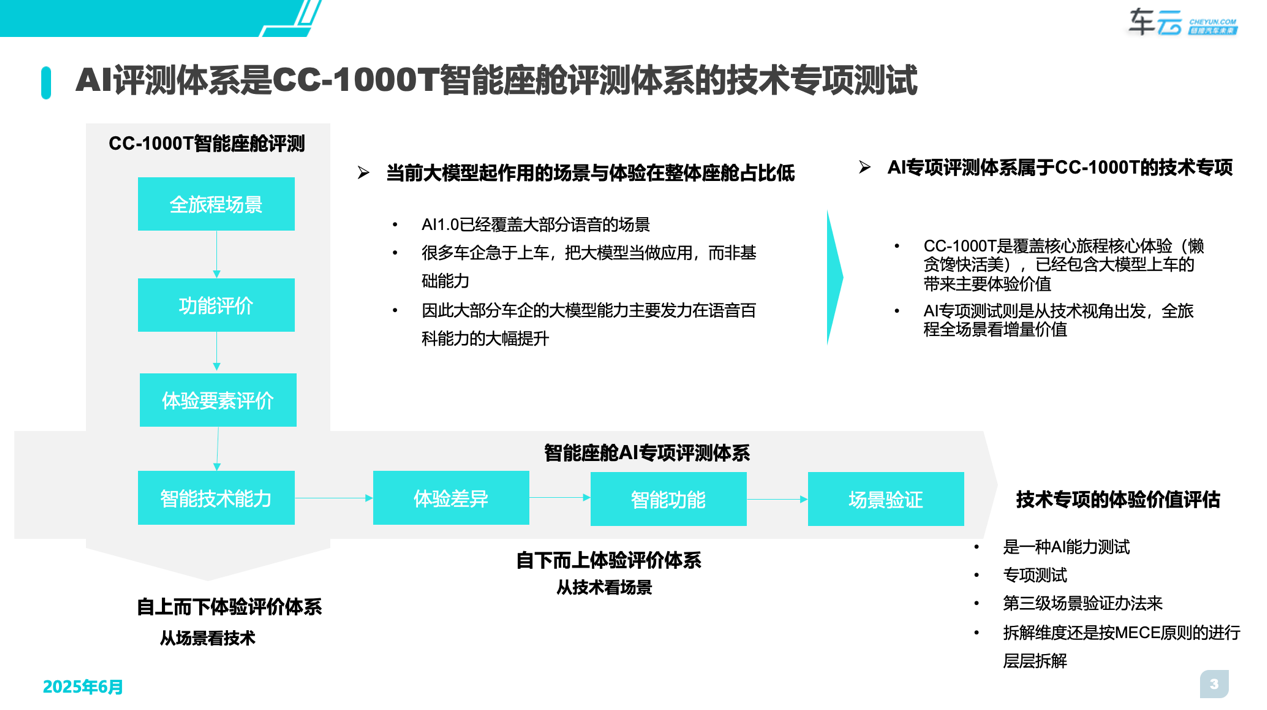
研究与搭建的过程中我们发现,当前AI大模型在智能座舱的用户体验中感知最高的依然聚焦在语音交互领域。而从用户的认知上传统的即AI1.0时代的语音交互是以“工具”属性为用户提供更加便捷的被动交互,而作为大模型赋能下的AI2.0时代的语音交互将以全新的“服务”属性为用户提供更加主动的移动智能体。当然从“工具”属性“向“服务”属性的转变依然会经历漫长的探索过程,但本着产品未至标准先行的原则,结合当前大模型在智能座舱领域的体验现状,车云研究院经过近半年的洞察与研究搭建出了《CC-1000T智能座舱AI专项评测体系》,目的是为各车企提供一把相对客观的第三方标尺。
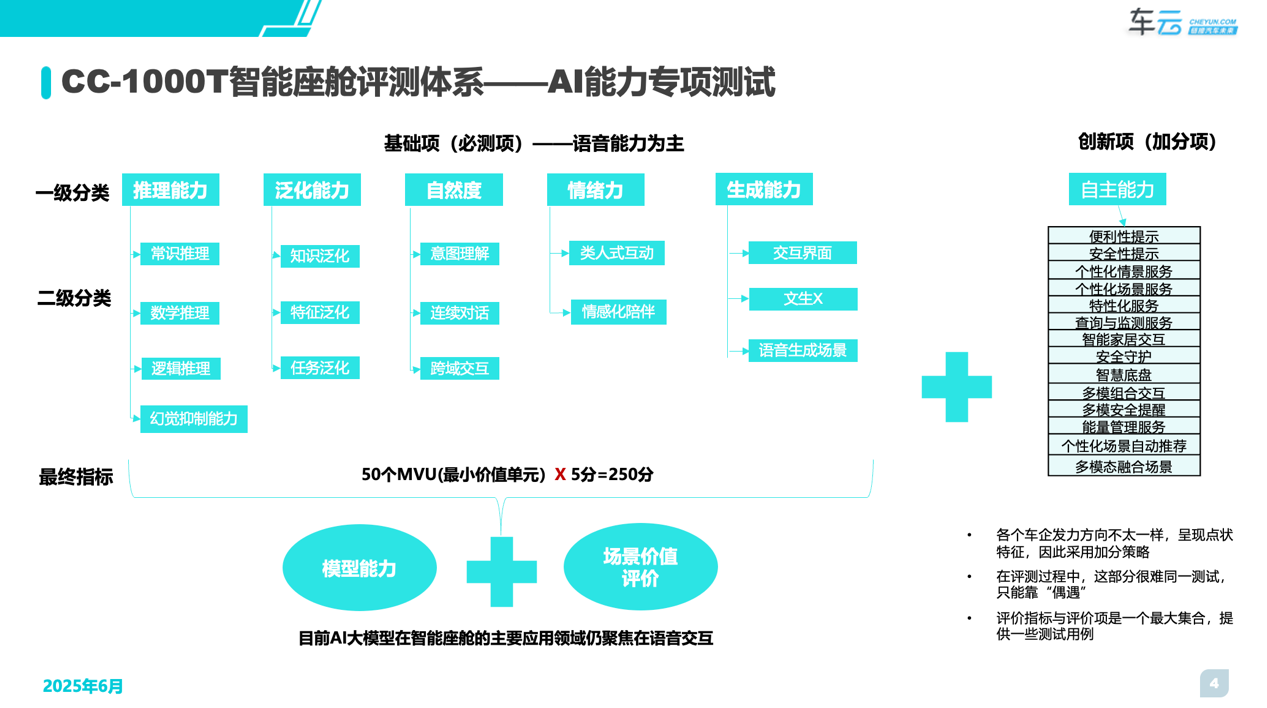
具体来看,AI专项评测体系主要覆盖了“5+1”的核心能力
“5”主要指的是基础必测项,主要以语音能力为主,即【推理能力】、【泛化能力】、【情绪能力】、【生成能力】、【自然程度】
“1”主要指的是创新加分项,主要以主动服务、多模态融合为主
整个AI专项评价体系涉及约50项评价内容,分别从模型能力和场景价值两个维度来衡量不同车型在AI大模型领域的体验差异。
接下来我们会针对以上6项核心能力的体系内容逐一进行解读。
能力1——【推理能力】
推理能力作为AI大模型最核心的能力之一,正从“数据压缩”迈向“世界模拟”, 从“数据拟合工具”向“认知决策体”跃迁,其本质是用计算重构人类认知金字塔的基石,是超越模式匹配的类人化思考。
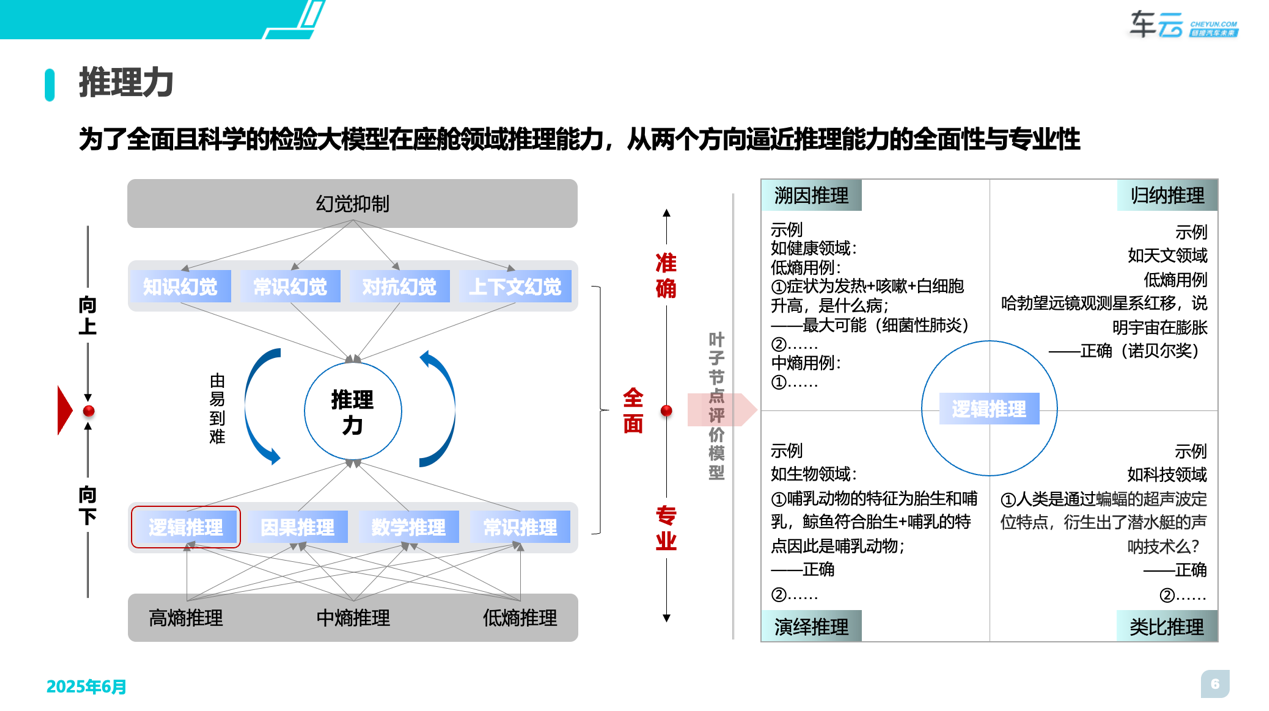
为了全面且科学的检验大模型在座舱领域的推理能力,我们将从两个方向逼近推理能力的全面性与专业性。
首先我们从“推理”本身将其分成了“逻辑推理”、“数学推理”、“常识推理”和“因果推理”,每一类推理又分成了“高熵”、“中熵”、“低熵”三个层次。同时AI大模型的诞生又伴随着AI幻觉的产生。因此AI幻觉的评价也是必不可少的内容,我们又从最常发生的“知识幻觉”、“常识幻觉”、“对抗幻觉”和“上下文幻觉”进行综合检验,进而保证推理能力的全面性和专业性。
以逻辑推理为例,每一个评价项目都会设计独立的评价模型,再辅以丰富的评价用例来确保评价的准确性。
示例【幻觉抑制】-“知识幻觉”、“对抗幻觉”、“常识幻觉”:
1. 知识幻觉:(事实性错误)
如:2000年奥运会在雅典召开的(2000年澳大利亚悉尼,2004年雅典)
2、对抗幻觉:(如矛盾性指令)
如:独在异乡为已客的上一句是什么?(该句即为第一句,没有上一句)
3、常识幻觉:(常识性错误)
如:“七月流火”是如何形容盛夏的酷热?(指夏去秋来,天气转凉,而非形容炎热)
能力2——【泛化能力】
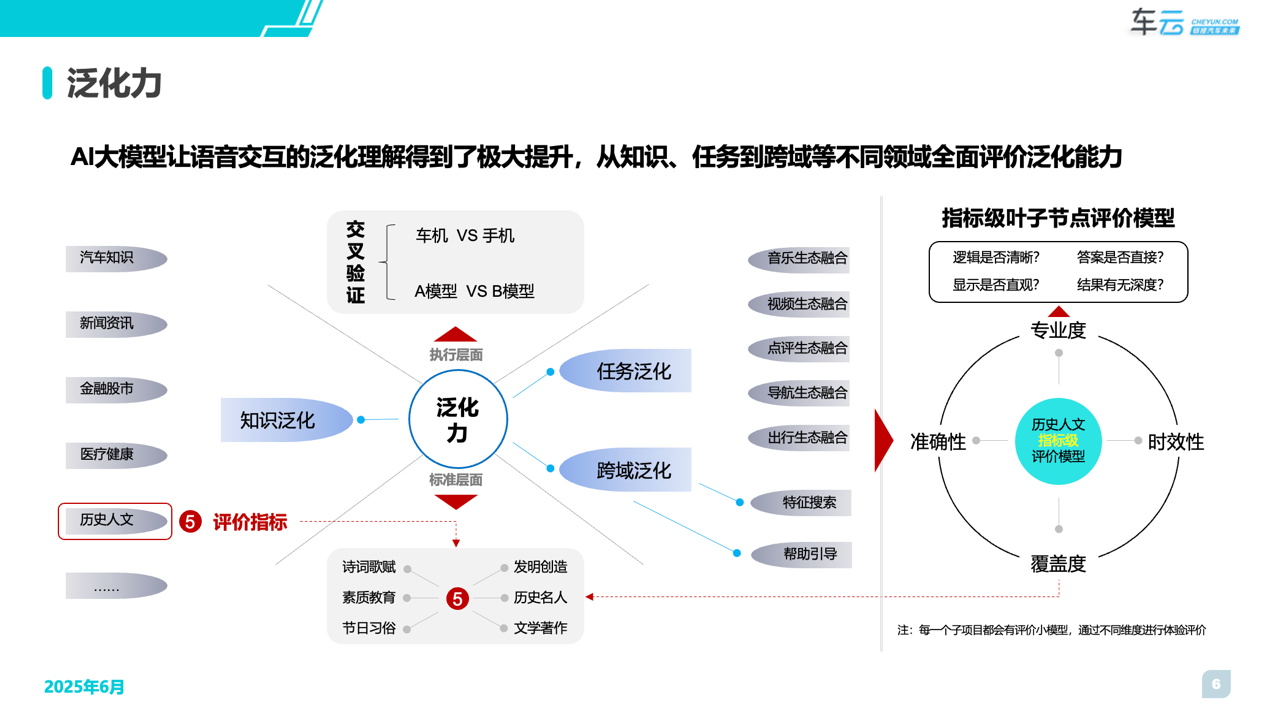
AI大模型的出现进一步提升了语音交互的泛化能力,主要表现为“知识泛化”、“任务泛化”和“跨域泛化”。根据用户在智能座舱域的用车场景与使用频率又分别进行了拆解,力求能够在泛化能力评价上从全面性与重要性两方面得到平衡。具体为:
1、【知识泛化】:拆解成5个垂类,分别为“汽车知识”、新闻资讯“、“金融股市”、“医疗健康”、“历史人文”。
2、【任务泛化】:拆解成5个任务,分别为“音乐任务融合”、“视频任务融合”、“导航任务融合”、“点评任务融合”、“出行任务融合”。
3、【跨域泛化】:拆解成2个内容,分别为“特征搜索”、“帮助引导”
以知识泛化中“历史人文”垂类查询为例,我们会从准确性、时效性、专业性和覆盖度四个维度进行评价,如覆盖度检验是否涵盖诗词歌赋、节日习俗、素质教育、发明创造、历史人名和文明著作,再通过手机大模型与车机大模型进行交叉验证。
 示例【泛化能力】-“任务泛化”:当用户在搜索某一个歌手/影星的信息时,如果大模型的介绍中有其相关代表作品,那么用户不需要在打开视频或音乐应用,只需要在大模型显示页面选择或语音选择即可观看或收听,提高了用户操作任务的效率。
示例【泛化能力】-“任务泛化”:当用户在搜索某一个歌手/影星的信息时,如果大模型的介绍中有其相关代表作品,那么用户不需要在打开视频或音乐应用,只需要在大模型显示页面选择或语音选择即可观看或收听,提高了用户操作任务的效率。

能力3——【情绪能力】
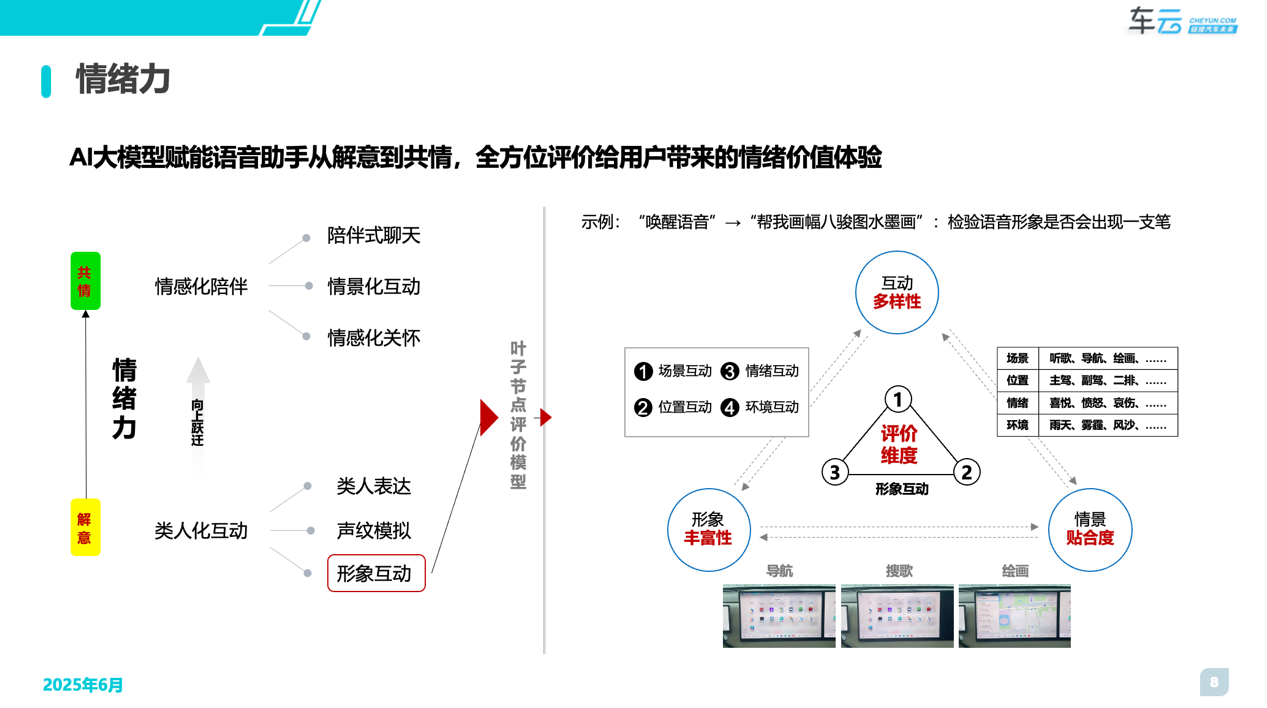
随着AI大模型多模态能力的增强,其互动性与陪伴性价值加速落地,旨在满足用户被理解、被倾听与被关注的需求。智能座舱通过语音交互从解意到共情,多角度为用户提供情绪价值。因此该部分能力的评价主要涉及两个方面:
1、【类人化互动】:包括“形象互动”、“声纹模拟”、“类人表达”
2、【情感化陪伴】:包括“情感化关怀”、“情景化互动”、“陪伴式聊天”
以【类人化互动】中的“形象互动”为例,我们会从互动的多样性、形象的丰富性与情景的贴合度三个维度进行综合评价。
 示例【类人化互动】-“声纹模拟”:家庭用车时经常会出现车内小朋友与语音助手互动,理想在打开小主人模式后当识别到儿童声纹时也会以儿童的语气回复,并且推荐儿童节目,增加了交互的互动性与趣味性。
示例【类人化互动】-“声纹模拟”:家庭用车时经常会出现车内小朋友与语音助手互动,理想在打开小主人模式后当识别到儿童声纹时也会以儿童的语气回复,并且推荐儿童节目,增加了交互的互动性与趣味性。

能力4——【自然程度】
大模型的出现补全了传统语音交互中语境理解的不足,通过对话语境的分析,大语言模型能够更加精准的捕捉用户的意图,全面提升自然语言理解能力和对话的自然感。
传统的语音交互也会涉及意图理解与连续对话等,AI专项评价体系是在传统语音交互 评价体系之上针对重要模块进行补充,主要包括:
1、【意图理解】:包括“模糊意图”、“冗余意图”、“简称理解”、“多意图理解”、”话题转移“
2、【连续对话】:包括“上下文理解”、“上下文记忆”
3、【跨域交互】:包括“跨语言交互”、“跨场景交互”、“跨空间交互”、“跨终端交互”、“跨生态交互”
以【连续对话】中“上下文理解”为例,我们把上下文理解共划分为3种情况,分别为场景内上下文理解、跨场景上下文理解和跨声区上下文理解,其中场景内上下文理解又分为7类高频垂域场景。每个评测项目都会根据垂域的丰富性、指代的准确性和意图的延续性进行综合打分。如【跨场景上下文理解】“你好XX” → “导航去张家界XX地点” → “那边天气怎么样”→“附近有没有什么美食推荐”。

示例【跨域交互】-“跨空间语音交互”:在用户开车快到家时想提前打开家里的窗帘/照明灯等智能设备,问界能够实现通过车机语音实现,不需要在打开智慧家居APP进行操作,极大减少了用户分心的同时便利性也得到了极大的提升。

能力5——【生成能力】
生成式AI作为大模型最重要的应用场景之一,是指利用机器学习模型来创建新的内容,包括且不限于文本、图片、音乐、音频、视频等。再利用多模态的特征对创建的不同内容进行处理、拓展和融合。具有很好的场景与价值潜力。
我们针对当前智能座舱应用场景与产品现状分析后,除了评价AI大模型生成的基础能力外,还针对场景生成能力和内容生成能力重点体验,具体指:
【基础能力】:主要包含“性能”(首词响应时间、出词速度、出图速度等)、“界面”(内容可读性、内容逻辑性、布局美观性等)、交互(自动播放匹配度、自定翻页匹配度等)
【内容生成】:主要包含“文本生成”、“图片生成”、“视频生成”
【场景生成】:主要包含“基于模糊指令生成”、“单一简单指令生成”、“复杂多条件指令生成”

示例【内容生成】-“文本生成”:陌生地点停车过程中车辆发生过潜在风险时,小鹏能够实现将哨兵视频中的内容生成文字摘要,让用户更高效,更及时的获取停车时发生的危险信息。

能力6——主动能力
基于多模态感知能力与AI大模型的分析决策能力,智能座舱从被动变得越来越主动,其特点为从传统基于规则的主动向基于模型的主动演化。
主动能力作为创新的一部分,整个行业仍处于场景探索和价值验证阶段,因此在评价过程中不设上限,但在创新性认定过程做了严格的要求。我们会从体验属性与价值属性两个维度进行评判,必须满足所有要求才会作为创新项。
价值属性:必须满足“惊喜+独创+实用”三个要求
体验属性:必须满足“服务主动性+需求必要性+场景契合度”三个要求
同时从当前产品现状看AI的座舱应用趋势主要包含两部分内容,主动服务和多模融合,在评价过程我们采用案头研究+实车评测两种方式进行评测,因为并非所有的主动能力场景都能够被还原。 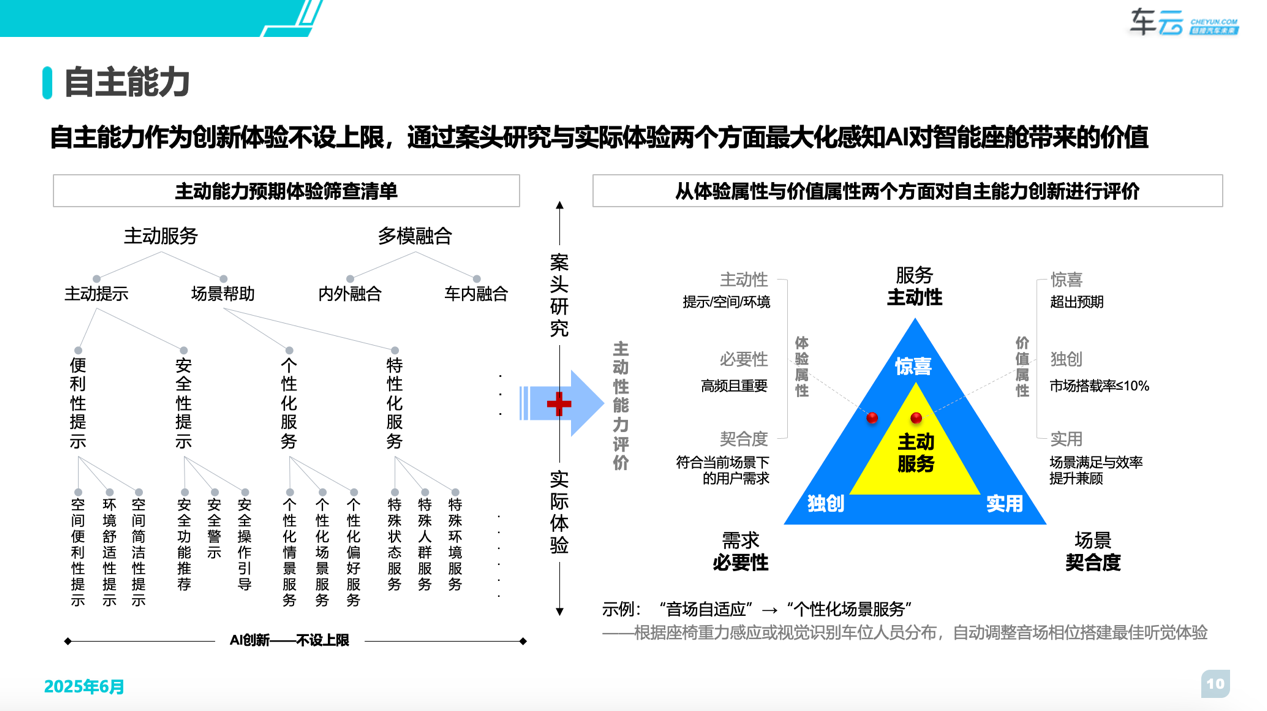
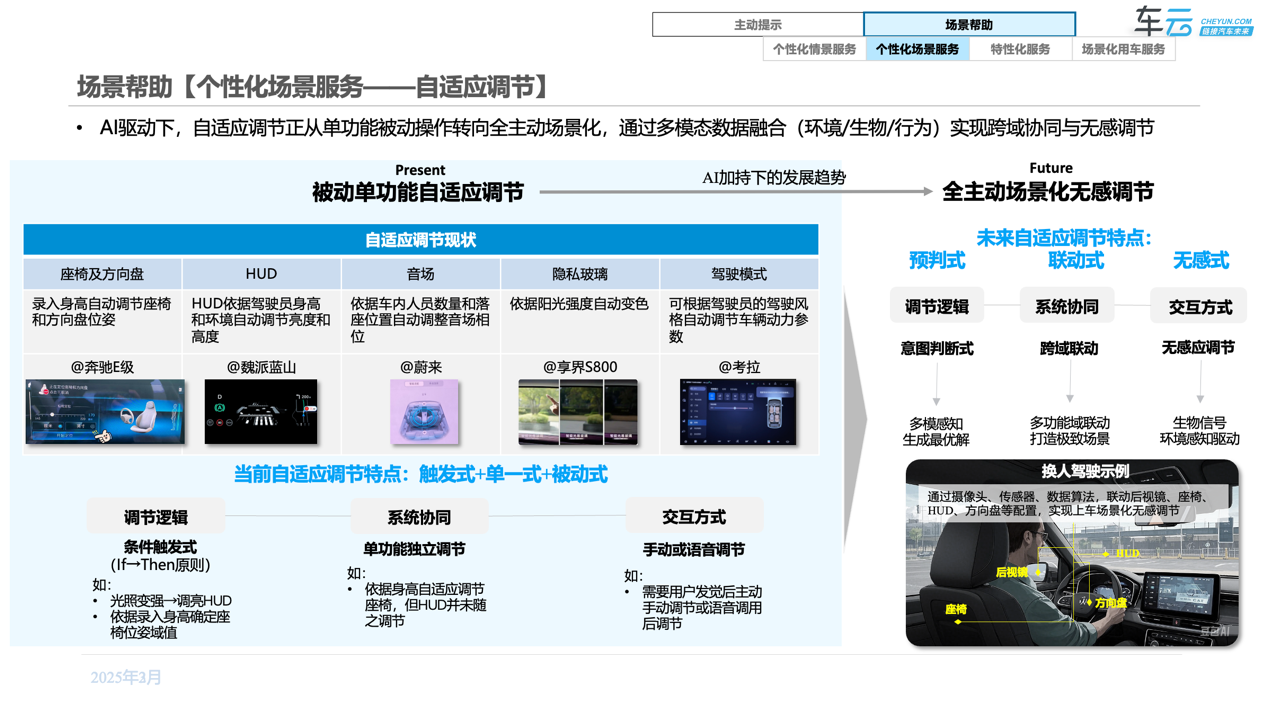
示例【场景帮助】-“个性化场景服务”:多个人在车内听音乐时,蔚来可以根据车内乘员的分布情况,自动调整音场的相位,不忽视每一位驾乘人员的听觉感受。
最后我们以该专项评价体系实践的两个实车评测结果作为结尾。
从两个头部新势力品牌的AI大模型基础评测项来看,其差异还是非常明显的,A车在推理、泛化、自然、清晰、生成五个方面全面领先于B车。其中高熵逻辑推理、任务泛化、连续对话中的上下文理解与内容生成中的场景符合度方面差异尤为明显。






时间|热度